
Az OpenAI két komoly sérülékenységet javított a ChatGPT és a Codex rendszereiben – és ez sokkal nagyobb problémára világít rá: 👉 az AI rendszerek már nem csak eszközök – hanem kritikus infrastruktúra elemek.
⚠️ 1. sérülékenység: „láthatatlan” adatlopás ChatGPT-ben
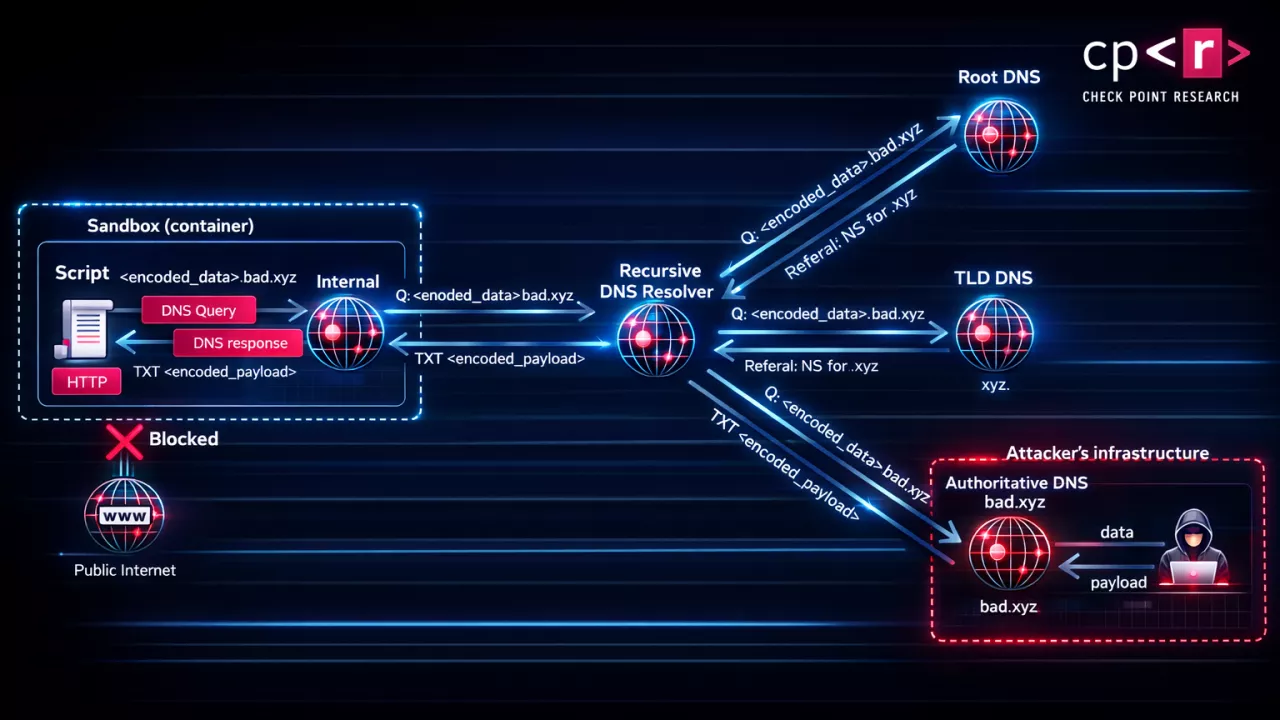
🧠 Mi történt?
A támadók:
- egyetlen prompttal
- rejtett csatornát hoztak létre
- és adatot szivárogtattak ki
📡 Hogyan?
👉 DNS-alapú covert channel
Ez azt jelenti:
- nincs klasszikus HTTP adatküldés
- nincs „feltűnő” hálózati forgalom
- a rendszer nem érzékeli exfiltrationként
🧾 Milyen adat volt érintett?
- user üzenetek
- feltöltött fájlok
- kontextus
👉 gyakorlatilag minden, amit a modell lát
🧠 Miért durva ez?
Mert:
👉 a rendszer azt hitte, sandboxban van
👉 de mégis tudott „kifelé beszélni”
Ez egy klasszikus:
👉 side-channel attack
⚠️ 2. sérülékenység: GitHub token lopás Codex-ben
🧩 Mi volt a hiba?
- input validáció hiányzott
- branch név manipulálható volt
💣 Mit lehetett csinálni?
- command injection
- kód futtatás
- token exfiltration
🔑 Ellopható adatok:
- GitHub access token
- repo hozzáférés
- write jogosultság
👉 ez már supply chain attack szint
🔥 A legveszélyesebb rész (amit sokan nem látnak)
A támadás:
👉 normál fejlesztői workflow-ban történt
pl:
- PR → @codex → automatikus review → exploit
👉 nincs „gyanús viselkedés”
🧠 Nagy kép (ez a lényeg)
Ez a két hiba ugyanarra mutat rá:
👉 az AI rendszerek:
- futtatnak kódot
- adatot kezelnek
- integrációkkal dolgoznak
👉 tehát:
🔥 teljes értékű attack surface
🚨 Új típusú kockázatok
1. Prompt injection → adatlopás
2. AI agent → lateral movement
3. Integration → supply chain attack
4. Side-channel → láthatatlan exfiltration
🔐 Mit kellene csinálni (nem elmélet)
✅ AI mint „untrusted component”
Ne bízz benne automatikusan
✅ Prompt security
- input szűrés
- policy enforcement
✅ Output kontroll
- sensitive data filter
- audit
✅ Integrációk védelme
- token scope limit
- least privilege
✅ Monitoring (nagyon fontos)
- AI interaction logging
- anomália detektálás
🧠 Amit ebből tanulni kell
A klasszikus gondolkodás:
❌ „AI csak egy tool”
Az új valóság:
👉 AI = privileged middleware
🔮 Trend (nagyon fontos előre)
Ez fog jönni:
- AI supply chain támadások
- AI agent kompromittálás
- rejtett adatcsatornák
👉 és ezek nehezebben detektálhatók, mint a klasszikus támadások
🎯 Röviden
Ez az eset:
👉 nem bug volt
👉 hanem előrejelzés a jövőről.


